This is the first entry in our series of “Unplugged” tutorials, in which we delve into the details of each of the time series models with which you are already familiar, highlighting the underlying assumptions and driving home the intuitions behind them.
In this issue, we tackle the ARMA model – a cornerstone in time series modeling. Unlike earlier analysis issues, we will start here with the ARMA process definition, state the inputs, outputs, parameters, stability constraints, assumptions, and finally draw a few guidelines for the modeling process.
Background
By definition, the auto-regressive moving average (ARMA) is a stationary stochastic process made up of sums of autoregressive Excel and moving average components.
Alternatively, in a simple formulation:
$$y_t-\phi _1y_{t-1}-\phi _2y_{t-2}-...-\phi_py_{t-p}=\mu +a_t+\theta _1 a_{t-1}+\theta _2 a_{t-2}+...+\theta _q a_{t-q}$$ $$OR$$ $$y_t=\mu +(\phi _1y_{t-1}-\phi _2y_{t-2}-\phi_py_{t-p})+(\theta _1 a_{t-1}+\theta _2 a_{t-2}+\theta _q a_{t-q})+a_t$$
Where:
- $y_t$ is the observed output at time t.
- $a_t$ is the innovation, shock, or error term at time t.
- $\left \{ a_t \right \}$ time series observations:
- Are independent and identically distributed $(a_t\sim i.i.d)$
- Follow a Gaussian distribution $(i.e. \Phi (0,\sigma ^2))$
Note:
The variance of the shocks distribution (i.e. $\sigma^2$) is time invariant.
Using back-shift notations (i.e. $L$), we can express the ARMA process as follows:
$$(1-\phi _1L-\phi_2L^2-...-\phi_pL^p)(y_t-\mu )=(1-\theta_1L-\theta _2L^2-...-\theta_pL^p)a_t$$
Assumptions
Let’s look closer at the formulation. The ARMA process is simply a weighted sum of the past output observations and shocks, with few key assumptions:
- The ARMA process generates a stationary time series ($\left \{ y_t \right \}$).
- The residuals $\left \{ a_t \right \}$ follow a stable Gaussian distribution.
- The components’ parameter $\left \{ \phi _1,\phi_2,...,\phi_p,\theta _1,\theta_2,...,\theta_p \right \}$ values are constants.
- The parameter $\left \{ \phi _1,\phi_2,...,\phi_p,\theta _1,\theta_2,...,\theta_p \right \}$ values yield a stationary ARMA process.
What do these assumptions mean?
A stochastic process is a counterpart of a deterministic process; it describes the evolution of a random variable over time. In our case, the random variable is $y_t$
Next, are the $\left \{ y_t\right \}$ values independent? Are they identically distributed? If so, $y_t$ should not be described by a stochastic process, but instead by a probabilistic distribution model.
For cases where $\left \{ y_t\right \}$ values are not independent (e.g. $y_t$ value is path-dependent), a stochastic model similar to ARMA is in order to capture the evolution of $y_t$.
The ARMA process only captures the serial correlation (i.e. auto-correlation) between the observations. In plain words, the ARMA process sums up the values of past observations, not their squared values or their logarithms, etc. Higher-order dependency mandates a different process (e.g. ARCH/GARCH, non-linear models, etc.).
There are numerous examples of a stochastic process where past values affect current ones. For instance, in a sales office that receives RFQs on an ongoing basis, some are realized as sales-won, some as sales-lost, and a few spilled over into the next month. As a result, in any given month, some of the sales-won cases originate as RFQs or are repeat sales from the prior months.
What are the shocks, innovations, or error terms?
This is a difficult question, and the answer is no less confusing. Still, let’s give it a try: In simple words, the error term in a given model is a catch-all bucket for all the variations that the model does not explain.
Confused? Let’s put it a different way. In any given system, there are possibly tens of variables that affect the evolution of $y_t$, but the model captures few of them and will bundle the rest as an error term in its formula (i.e. $a_t$ ).
Still lost? Let’s use an example. For a stock price process, there are possibly hundreds of factors that drive the price level up/down, including:
- Dividends and Split announcements
- Quarterly earnings reports
- Merger and acquisition (M&A) activities
- Legal events, e.g. the threat of class action lawsuits.
- Others
A model, by design, is a simplification of a complex reality, so whatever we leave outside the model is automatically bundled in the error term.
The ARMA process assumes that the collective effect of all those factors acts more or less like Gaussian noise.
Why do we care about past shocks?
Unlike a regression model, the occurrence of a stimulus (e.g. shock) may have an effect on the current level, and possibly future levels. For instance, a corporate event (e.g. M&A activity) affects the underlying company’s stock price, but the change may take some time to have its full impact, as market participants absorb/analyze the available information and react accordingly.
This begs the question: don’t the past values of the output already have the shocks’ past information?
YES, the shocks history is already accounted for in the past output levels. An ARMA model can be solely represented as a pure auto-regressive (AR) model, but the storage requirement of such a system is infinite. This is the sole reason to include the MA component: to save on storage and simplify the formulation.
$$(1-\phi _1L-\phi_2L^2-...-\phi_pL^p)(y_t-\mu )=(1-\theta_1L-\theta _2L^2-...-\theta_pL^p)a_t$$ $$\frac{(1-\phi _1L-\phi_2L^2-...-\phi_pL^p)}{(1+\phi _1L+\phi_2L^2+...+\phi_pL^p)}(y_t-\mu )=a(t)$$ $$(1-\psi _1L-\psi _2L^2-\psi_3L^3-...-\psi_NL^N-...)(y_t-\mu )=a_t$$
ARMA Machine
The ARMA process is a simple machine that retains limited information about its past outputs and the shocks it has experienced. In a more systematic view, the ARMA process or machine can be viewed as below:
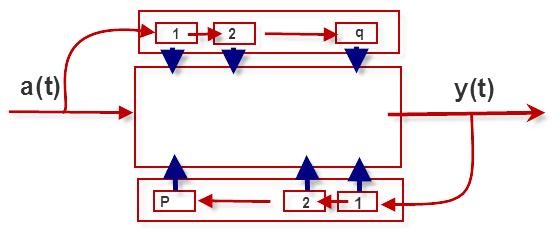
In essence, the physical implementation of an ARMA(P, Q) process requires P+Q storages, or the memory requirements of an ARMA(P, Q ) are finite (P+Q).
At time zero (0), the ARMA machine is reset and all its storages (i.e.$\left \{S_1^y,S_2^y,...,S_p^y,S_1^a,S_2^a,...,S_q^a \right \}$) are set to zero. As new shocks (i.e. $a_t$) begin to arrive in our system, the internal storages get updated with the new observed output ($y_t$) and realized shocks.
Furthermore, the AR component in the ARMA represents positive feedback (adding the weighted sum of the past output), and this may cause the output to be non-stationary. The feedback effect for the shocks is less of a concern, as the shocks have zero mean and are independent.
For a stable (i.e. stationary) ARMA process, the roots of the characteristic AR equation must be within a unit-circle.
$$1-\phi _1L-\phi_2L^2-...-\phi_pL^p=(1-\gamma _1L)(1-\gamma_2L)...(1-\gamma_p L)$$ $$\left | \gamma_k \right |< 1$$
Where:
- $\gamma_k$ is the k-th root.
- $1\leq k\leq p$
Note:
in the event that the MA and AR components have any common root, the ARMA orders (i.e. P and Q) should be reduced.
Stationary ARMA
Now that we have a stationary (stable) ARMA process, let’s shift gears and examine the output series characteristics.
$$y_t-\phi _1y_{t-1}-\phi_1y_{t-2}-...-\phi_py_{t-p}=\mu +a_t+\theta _1a_{t-1}+\theta _2a_{t-2}+...+\theta _qa_{t-q}$$
Marginal mean (long-run mean)
$$E\left [ y_t \right ]=E\left [ \mu +\phi _1y_{t-1}+\phi_1y_{t-2}+...-\phi_py_{t-p}+a_t+\theta _1a_{t-1}+\theta _2a_{t-2}+...+\theta _qa_{t-q} \right ]$$ $$E\left [ y_t \right ]= \mu +\phi _1E\left [y_{t-1} \right ] +\phi _2E\left [y_{t-2} \right ]+...+\phi _pE\left [y_{t-p} \right ]$$ $$E\left [ y_t \right ]= \frac{\mu }{1-\phi _1-\phi_2-...-\phi_p}$$
For a stationary ARMA process, the $\sum_{k-1}^{p}\phi_k\neq1$
Marginal variance (long-run variance)
The formula for the long-term variance of an ARMA model is more involved: to solve for it, I derive the MA representation of the ARMA process, after which I take the variance since all terms are independent.
For illustration, let’s consider the ARMA (1, 1) process:
$$(1-\phi L)(y_t-\mu)=(1+\theta L)a_t$$ $$y_t-\mu=\frac{1+\theta L}{1-\phi L}a_t=(1+(\phi+\theta)L+\phi(\phi+\theta)L^2+\phi^2(\phi+\theta)L^3+...+\phi^{N-1}(\phi+\theta)L^N+...)a_t$$ $$y_t-\mu=a_t+(\phi+\theta)a_{t-1}+\phi(\phi+\theta)a_{t-2}+...+\phi^{N-1}(\phi+\theta)a_{t-n}+...$$ $$Var\left [ y_t-\mu \right ]=Var\left [ y_t \right ]=(1+(\phi+\theta)^2+\phi^2(\phi+\theta)^2+...+\phi^{2N-2}(\phi+\theta)^2+...) \sigma _a^2$$ $$Var\left [ y_t\right ]=Var\left [ y_t \right ]=(1+(\phi+\theta)^2(1+\phi^2+\phi^4+...+\phi^{2N-2}+...))\sigma _a^2=(1+\frac{(\phi+\theta)^2}{1-\phi^2})\sigma _a^2$$ $$\sigma_y^2=(\frac{1+2\theta\phi+\theta^2}{1-\phi^2})\sigma_a^2$$
Again, the ARMA process must be stationary for the marginal (unconditional) variance to exist.
Note:
In my discussion above, I am not making a distinction between merely the absence of a unit root in the characteristic equation and the stationarity of the process. They are related, but the absence of a unit root is not a guarantee of stationarity. Still, the unit root must lie inside the unit circle to be accurate.
Conclusion
Let’s recap what we have done so far. First, we examined a stationary ARMA process, along with its formulation, inputs, assumptions, and storage requirements. Next, we showed that an ARMA process incorporates its output values (auto-correlation) and shocks it experienced earlier in the current output. Finally, we showed that the stationary ARMA process produces a time series with a stable long-run mean and variance.
In our data analysis, before we propose an ARMA model, we ought to verify the stationarity assumption and the finite memory requirements.
- In the event the data series exhibits a deterministic trend, we need to remove (de-trend) it first, and then use the residuals for ARMA.
- In the event the data set exhibits a stochastic trend (e.g. random walk) or seasonality, we need to entertain ARIMA/SARIMA.
- Finally, the correlogram (i.e. ACF/PACF) can be used to gauge the memory requirement of the model; we should expect either ACF or PACF to decay quickly after a few lags. If not, this can be a sign of non-stationarity or a long-term pattern (e.g. ARFIMA).
Comments
Article is closed for comments.