Background
A few years back, users requested a more modern interface in MS Excel to the popular X12-ARIMA, and its seasonal adjustment methodology (X11). The US Census Bureau developed and maintains the X12-ARIMA program (X12A), so it is freely available, and almost everyone in the business accepts and regards the X12A program and its methodology highly.
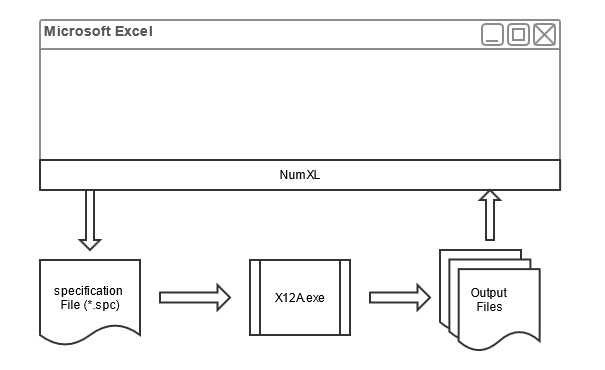
At that time, we opted to integrate NumXL with X12ARIMA, but as an external program.
What does integration with external programs mean?
In a nutshell, NumXL implements several excel functions and offers a user interface to accept users’ inputs and data. Behind the scenes, NumXL transfers the data and the user’s inputs back to the X12A program to do the calculation, and when finished, NumXL brings the outputs back to the user into Excel.
Why should you care?
We are assuming you are already using X12A/X11, and we wish to share some of the tips and workarounds we composed to overcome some of X12A's limitations to optimize your model’s run-time and responsiveness.
Whether you have one X12ARIMA model or hundreds of models, your workbook should be able to handle them.
Warning
Starting with version 1.67 (MARTHA), NumXL supports the latest U.S. Census X13ARIMA-SEATS seasonal adjustment software. The U.S. Census does not maintain the X12ARIMA seasonal adjustment software, and NumXL includes this model to help our customers migrate existing X12 models to the X13 equivalents.
Problem 1: X12A limitation for input data length
The US Census X12 ARIMA accepts time series of length from 12 (for monthly), and 4 for quarterly data, all the way to 600 observations.
NumXL functions accept a time series of any length, but only use the most recent 600 (non-missing) observations for X12A purposes and shift the start date accordingly.
As a user, you don’t have to change anything, you pass the data as you usually do, and NumXL handles this constraint behind the scene.
Problem 2: Add new observation to the data series
As time moves on, new observations are realized and appended to the input data set. We should refine the X12ARIMA definition to include these observations and re-run the model to update the seasonal adjustment and the forecast.
The scenario above may sound intuitive but bear in mind that you’d need to alter input cells-range in the formula of every X12ARIMA model in your workbook. This is not an issue for one series, but what about tens or hundreds of time series and corresponding models? You’d need to repeat the same exercise periodically, and thus we needed a better approach.
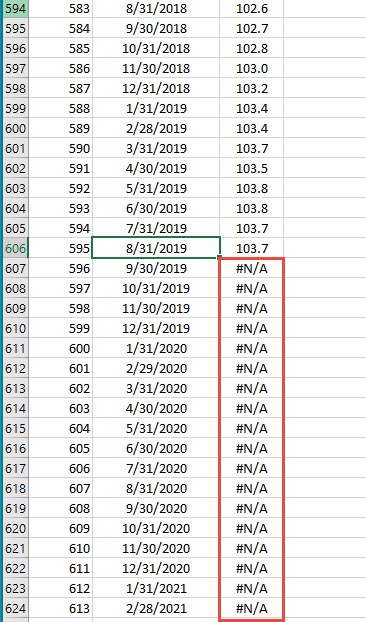
The workaround is the same as the one we illustrated in the tip: “How to Setup Regression Analysis to Update Automatically.” We append a “#N/A” after the end of your input data to reserve them. Next, Include those cells in the X12ARIMA model definition.
Initially, NumXL ignores all “#N/A” occurring after the last observation with a non-missing value. Later, as a new data point is realized, we replace the #N/A with an actual number, thus growing the input data set.
This technique adds a new observation to the input data set without the need to edit the definition formula. You’d still need to recalculate to update the model’s outputs.
Problem 3: The time spent building the models is too long!
The X12A performs a full set of model selection and calibration, so if your worksheet has more than a few X12ARIMA models, calculating the whole sheet takes more than a few seconds.
The workaround of this issue consists of two parts:
- Disable the auto calculation and set it to Manual.
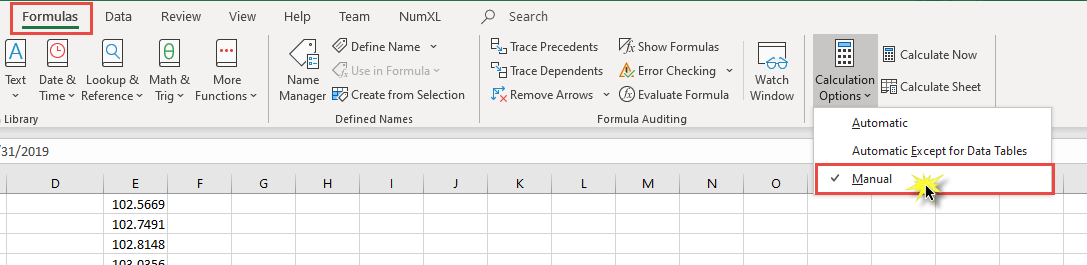
By setting the calculation to Manual, excel will not attempt to force a calculation when a cell is touched or changes its value. Instead, you’d need to start the calculation by hitting F9 or SHIFT+F9.
In the meanwhile, you can make many changes, while excel still is very responsive. - Disable the X12ARIMA disk cleanup and leave the generated X12ARIMA intermediate files on the disk.
Go to the NumXL installation directory (i.e., C:\users\<username>\AppData\Roaming\NumXL), and open the NumXL.conf file with notepad or your favorite text editor.
Locate the entry “CLEANUP_EXIT” under the X12ARIMA section.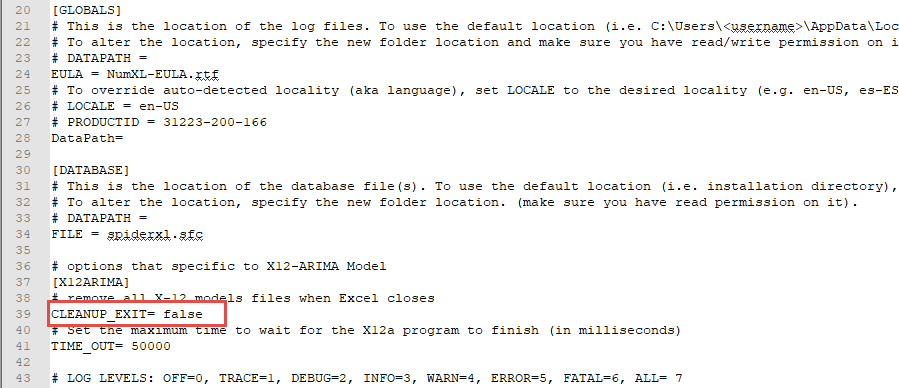
Make sure the corresponding value is set to “false.”
Note: substitute the <username> with your actual windows login name.
Now, when you open the workbook, NumXL will load (on a need-basis) the stored models and their output, without the need to run the X12A program.
Problem 4: My data feed is touching many cells.
In many environments, data feed programs generate and update (on-demand or periodically) the input data used in X12ARIMA models. This setup is very intriguing, but the input cells are being touched often, and Excel triggers massive scale scores of calculation requests, so when running a manual calculation, many models are candidates for re-evaluation.
In NumXL, we compute and store the checksum internally (aka. Hash) for the input data set and for the values of the model’s parameters. So, when Excel makes a new model evaluation request, NumXL computes the new checksums and compares them against the ones we already have. If NumXL does not find any changes, it simply ignores the request.
As a result, no matter how many X12ARIMA models you have, NumXL only evaluates those with inputs (i.e., model’s parameters or input data) that have genuinely changed since the last run. Thus, X12ARIMA runs when needed.
Problem 5: Missing values (#N/A)
The US census X12A program does not handle missing values, but missing values are beneficial, as we have seen in Problem 2.
NumXL accepts input data sets with missing values before the beginning or after the end of the (non-missing) dataset. NumXL does not support intermediate observations with missing values.
You may wonder why do we need to insert observations with missing values before the start of the input data set. Users always wish to line up their data sets to start in the same row, but data sets may have different start dates, so by stuffing #N/A at the beginning, we can make all time series start on the same date.
Adding observations with missing values at either end of the time series does not affect the output, as NumXL adjusts the start date (and the finish date) to the dates of the nearest non-missing observations.
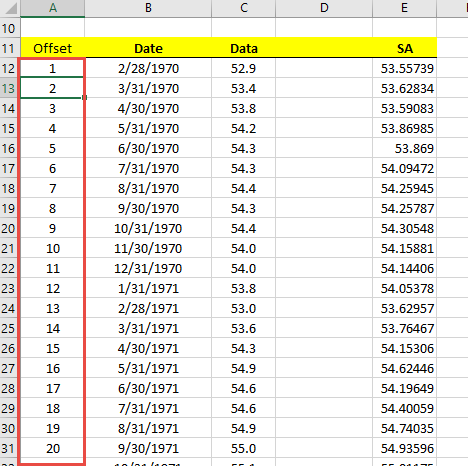
Problem 6: Offset argument in X12ACOMP
To display any of the X12ARIMA output time series (e.g., seasonally adjusted), the user should use the worksheet function X12ACOMP(), but this function expects: a model name, output type, and offset.
The offset is the number of observations from the beginning of the input data set. The observations should include those with missing values (i.e., stuffed at the beginning).
To calculate the offset, you can either populate a column with an integer sequence, starting at one (1), and increase as it goes down.
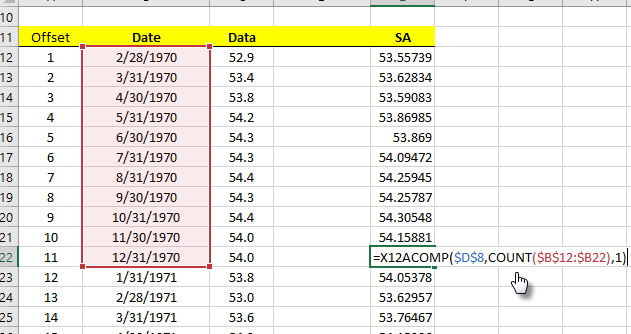
Another approach is to use Excel’s built-in function COUNT() and calculate the number of cells from the beginning of the input data to our current position.
Problem 7: IT/MIS policy restrictions
In some environments, the IT/MIS sets restrictive security policies preventing programs from running in the users’ local profile (i.e., C:\users\<username>\AppData\LocalData). This setup forbids the X12A program from running, thus, generating any outputs.
The workaround for this issue is to change the “data directory” setup in the “NumXL.conf” file, to a directory where the user has enough permission to run programs.
To do so, Go to the NumXL installation directory (i.e., C:\users\<username>\AppData\Roaming\NumXL), and open the NumXL.conf file with notepad or your favorite text editor.

Locate the entry “DATAPATH” under the [GLOBASLS] section, uncomment (delete the hashtag), and set its value to a directory on your disk with enough permission to run the X12A program.
Conclusion
In this issue, we presented a series of challenges encountered by our users while using the NumXL X12ARIMA model in Excel for everyday use. For each case, we showed the corresponding enhancement, recommendation, and in some cases, workarounds to overcome it.
Looking forward, we are taking those valuable lessons with us, as we are rolling on the latest X13ARIMA-SEATS program from the US Census.
Comments
Please sign in to leave a comment.