The topic of this newsletter is about setting up a forecasting model (e.g., ARMA, GARCH, Regression) in such a way that you (or someone else) can readily maintain it as new data points become available and forecasts are auto-updated.
To demonstrate, we defined a GARCH model for the S&P 500 ETF monthly returns, calibrated the parameters' values, and constructed a volatility forecast term structure for the following 36 months. We then plugged in a new data point and observed the model advancing the forecast start date and updating forecast values.
Why should you care?
In practice, we create many excel-based models, some of them for single-use, but many spreadsheets are often shared with colleagues, revised occasionally, and linger around for a long time. Preparing your worksheet for an auto-update is relatively simple. Once done, you can easily add new data points or revise existing ones and see your calculations updated with minimal effort.
Ready, let's dig in!
Data Preparation
For this tutorial, we are using the monthly log-returns of the S&P 500 ETF (SPY) between January 2010 and November 2019:
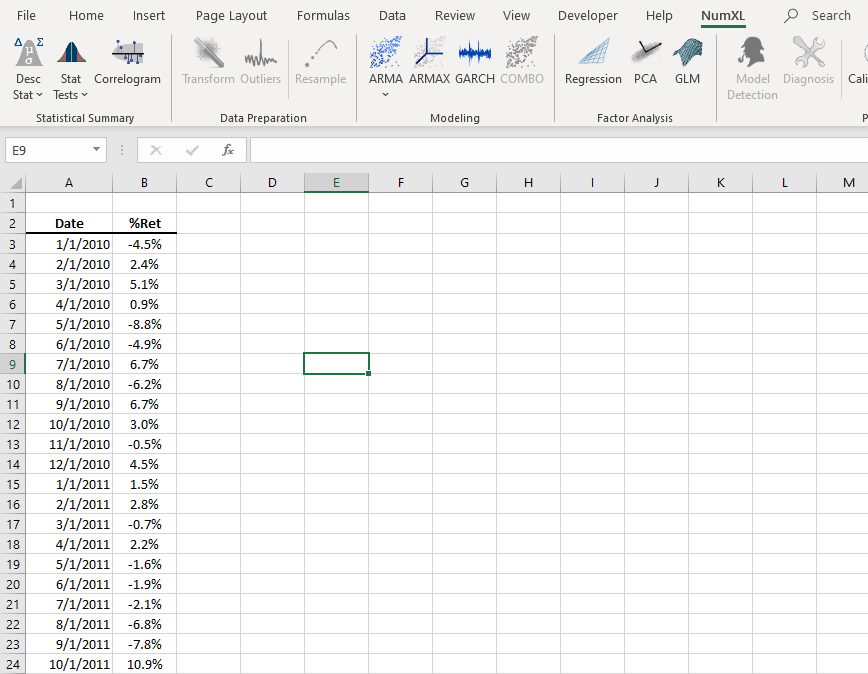
First, we should append the current dataset with placeholders. We do so by advancing dates (e.g., Dec. 2019, Jan. 2019) and entering "#N/A" as their values.
Modeling
We chose a GARCH(2,2) with the student's innovations to capture the time-varying monthly volatility dynamic for this data set. To define the model, locate an empty cell in your worksheet, and then click on the "GARCH" icon in the "NumXL" toolbar, and the GARCH wizard pops up.
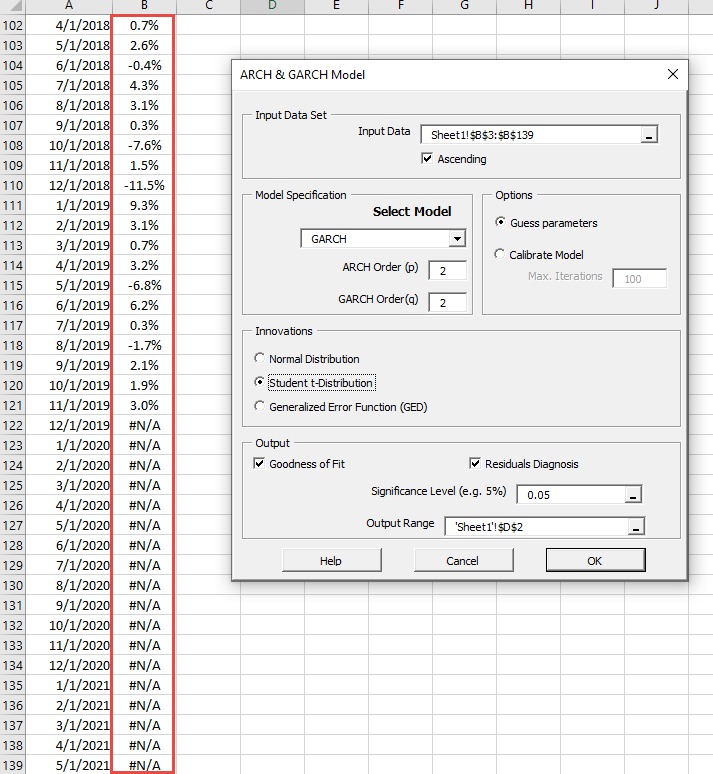
In the ‘Input Data’ section, select the monthly returns' cell range, including the placeholders you added earlier. Not to worry, the NumXL functions will discard observations with "#N/A" values at either end of the input cell range.
Select the ARCH and GARCH in the Model Specifications section, and set the order to 2. Click on "Student t-distribution" under the innovations section. Now, click on the "OK" button to confirm your selection.
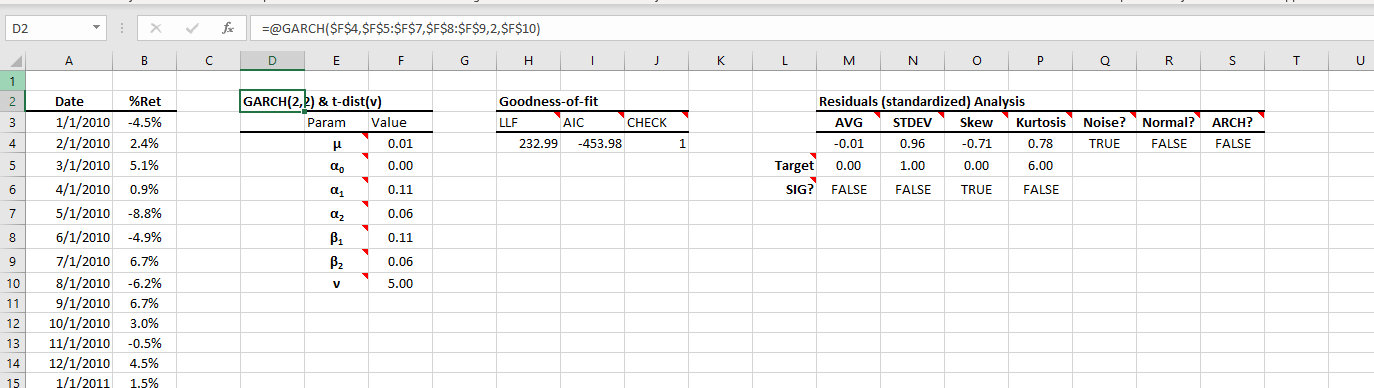
The GARCH wizard generates the model table and initializes its parameters' values to valid but sub-optimal values. To find an optimal set of values for the GARCH parameters, select the model table's header cell and click on the "Calibrate" icon in the "NumXL" toolbar. Microsoft Solver pops up with all its values set. Click Solve
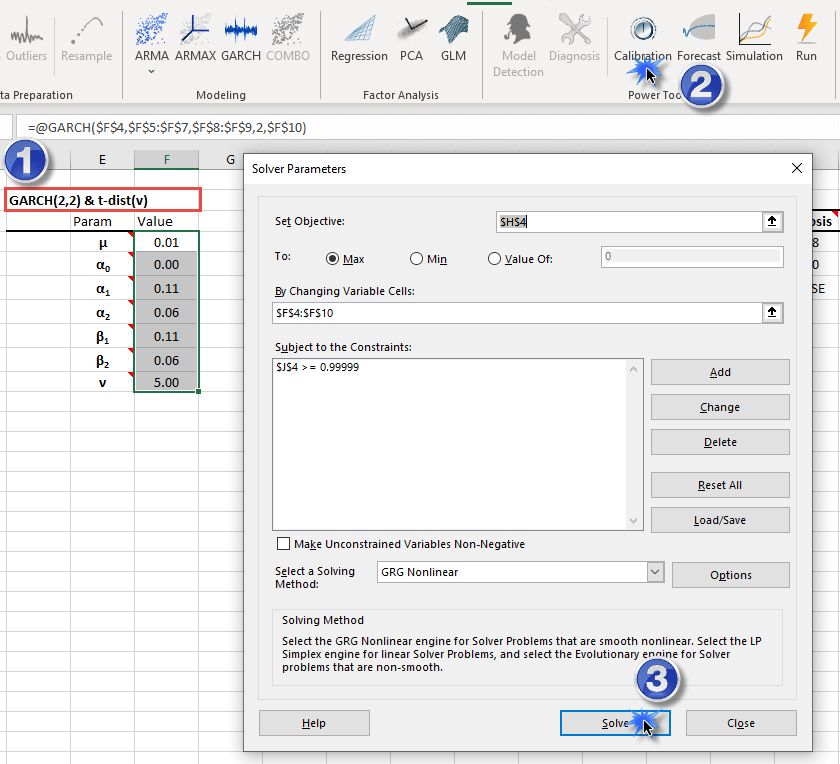
Microsoft solver searches for an optimal solution for the GARCH process.
Data Exploration
Earlier, we mentioned that the NumXL functions discard any observation in the input cell range with a value equal to "#N/A". How do you know where the dataset ends?
To answer the question above, you need to first calculate the dataset's size with two functions: RMNA(.) and COUNT(.). The RMNA(.) discards datapoints with "#N/A" and returns an array of all non-missing observations, and the COUNT(.) returns the size of this array.

You can also calculate the end date of the dataset using the Excel built-in INDEX(.) function and the dataset size above.
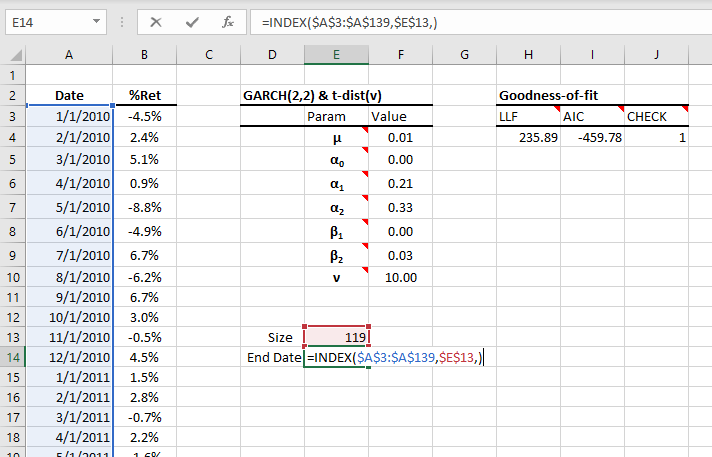
In sum, you have a dataset of 119 non-missing values, and the latest observation fell in November 2019.
Forecasting
for this tutorial, you need to construct the monthly volatility forecast for the following 36 months. To do so, select the model table's header row and click on the "Forecast" icon in the NumXL toolbar.
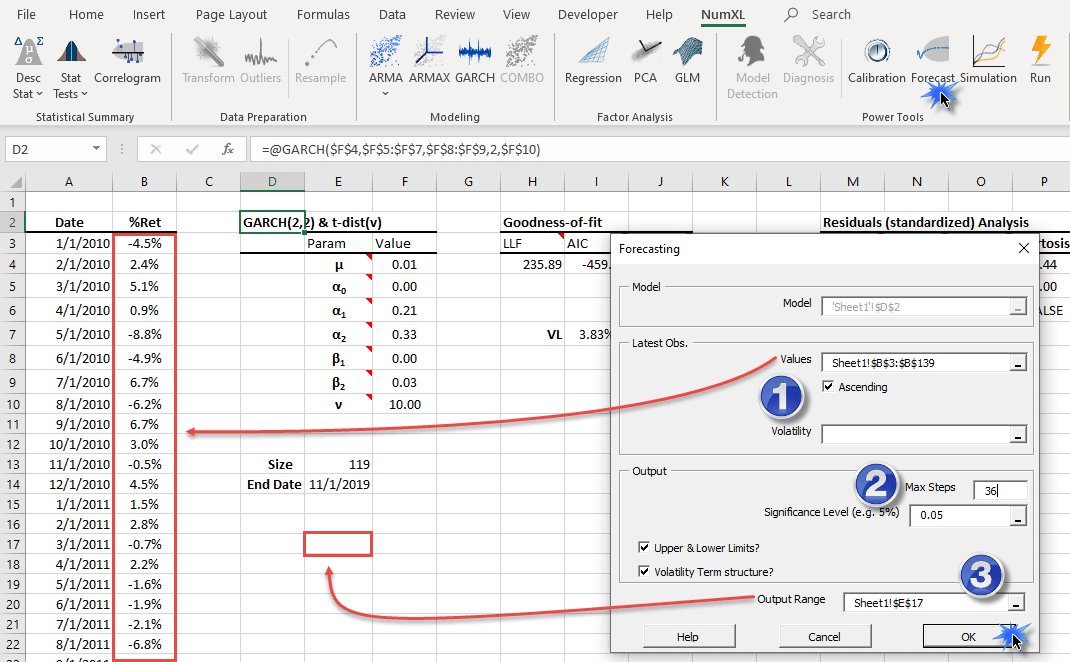
In the "Latest obs." section, select the cell range in column "B," including the observation with missing values (i.e., #N/A).
For the volatility, leave it blank, and NumXL will use the in-sample volatility computed by the GARCH model itself. Click the "OK" button.
The forecast wizard generates a forecast table that expresses the time unit in terms of steps (i.e., month) measured after the input dataset's end.

Over time, adding new data points advances the last observation's (with non-missing value) date, impacting our interpretation of the step-unit in the forecasting table. To counter this problem, we added a column on the left of the forecast table to designate the corresponding calendar date.
To calculate the corresponding date for each step, we will NxEDATE(.) and CONCAT(.) functions, as shown below:
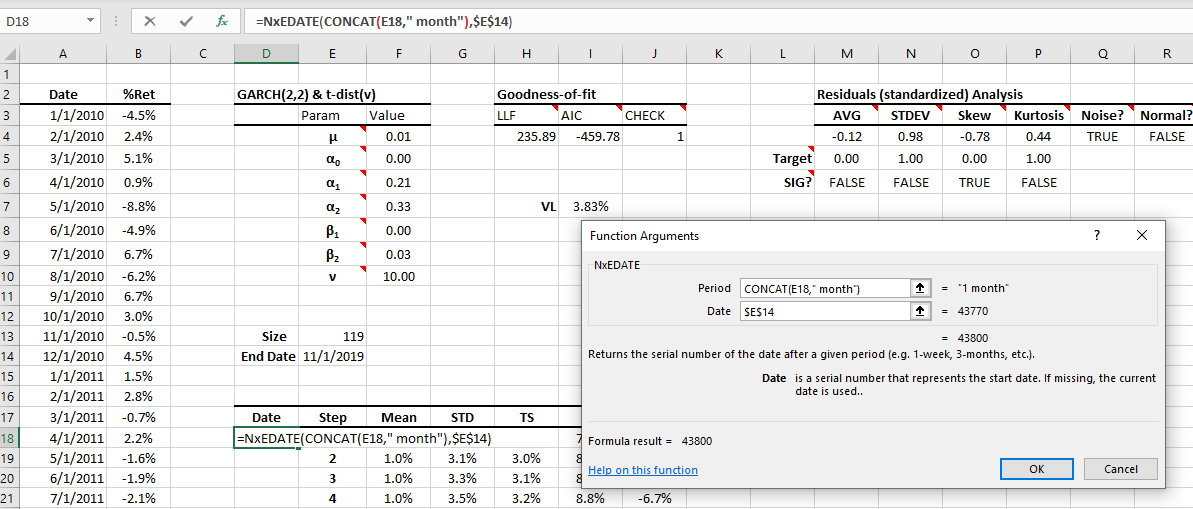
Using the dataset end-date, the NxEDATE(.) returns the data that falls after N-months, where N is the number of steps in the forecast table.
What happens if the new data falls on a weekend or a holiday? Since our dataset is a financial time series, the date must fall on a workday; otherwise, move the date to the next nearest working date (NxAdjust(.)).
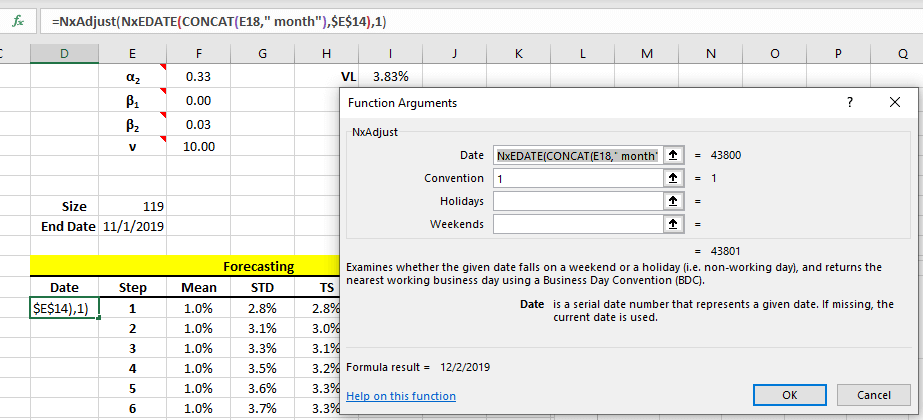
That's it! Let's examine the forecast table and the monthly volatility term structure curve.

The GARCH model reveals a low volatility environment – relative to the historical level (i.e., 3.8%) but forecasts a steady rise in volatility over the coming year.
Adding datapoints
Let's examine what happens when we have the monthly return of December 2019, say -0.6%.
Step 1: Enter the new value in the dataset.
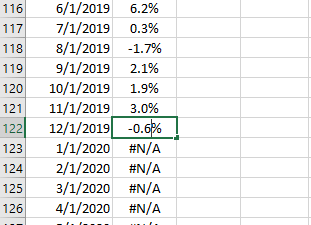
Step 2: Observe

The input dataset size increased to 120, and the end date is now Dec 2019.
In the forecast table, the corresponding date for step one is now January 2020 (was Dec 2019), and the volatility term structure is different (less smooth).
Step 3: Advanced
The forecast table above uses the same GARCH process that we calibrated earlier, especially the parameters' value.
For the sake of argument, let's assume you wish to re-calibrate the model but keep the ARCH/GARCH orders (i.e., P and Q) and the innovation distribution (e.g., student t) the same.
Like we did earlier, locate and select the GARCH model table's header row and click on the "Calibrate" icon in the NumXL toolbar.
The Solver pops up, but this time, the optimization will start (i.e., initial value) with the parameters' optimal values from the last run. Thus, we expect a rapid conversion.

Click on the "Solver" button to commence the optimization process.
Upon completion, the Solver displays a "Find Solution" dialog. Click the OK button, and it will copy the values of the new parameters into the model table.
To examine the re-calibration impact on your forecast, look down at your forecast values in the table (and plot).
Conclusion
In this tutorial, we examined the two steps to set up your models for auto-update:
- Adding placeholder datapoints at the end of the input dataset,
- Select the dataset with the placeholder datapoints into the model and forecast.
As time progress and new observation realizes, we enter their actual values into the dataset (in place of the #N/A), and Excel updates calculation of all referencing cells (e.g., forecast table).
Comments
Please sign in to leave a comment.