Esta es la tercera entrada en nuestra serie de análisis de regresión y modelado. En este tutorial, continuamos la discusión de análisis que iniciamos anteriormente aprovechando una técnica más avanzada - el análisis de datos influyentes - para ayudarnos a mejorar el modelo y, como resultado, la confiabilidad del pronóstico.
Una vez más, vamos a utilizar un conjunto de datos de muestra recogidos de 20 personas de ventas diferentes. El modelo de regresión intenta explicar y predecir las ventas semanales de cada persona (variable dependiente) utilizando dos variables explicativas: inteligencia (IQ) y extroversión.
Preparación de datos
Similar a lo que hicimos en nuestro tutorial anterior, organizamos los datos de muestra colocando el valor de cada variable en una columna separada y cada observación en una fila separada.
A continuación, introducimos la "máscara". La "máscara" es un array o matriz booleana (0,1) que elige qué variable se incluye (o excluye) en el análisis.
Inicialmente, en la parte superior de la tabla, vamos a insertar la matriz de la célula de máscara; Cada uno con un valor de 1 (es decir, incluido). La matriz se muestra a continuación resaltada a continuación:
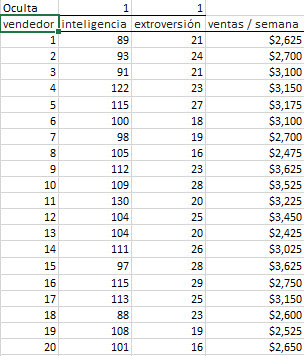
En este ejemplo, tenemos 20 observaciones y dos variables (explicativas) independientes. La respuesta o variable dependiente son las ventas semanales.
Proceso
Ahora estamos listos para llevar a cabo nuestro análisis de regresión. En primer lugar, seleccione una celda vacía en la hoja de cálculo donde desea que se genere la salida, a continuación, busque y haga clic en el icono de regresión en el NumXL.
![]()
Ahora el asistente de Regresión aparecerá.
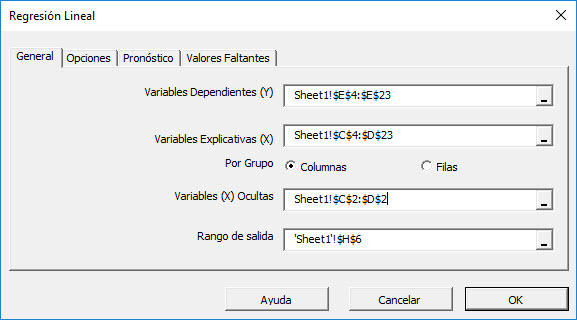
Seleccione el rango de celdas para los valores de la variable de respuesta / dependiente (es decir, las ventas semanales). Seleccione el rango de celdas para los valores de las variables explicativas (independientes). Para "Variables (X) Mask", seleccione las celdas en la parte superior de la tabla de datos (matriz booleana).
Notas:
- El rango de celdas incluye (opcional) la celda de encabezamiento ("Etiqueta"), que se utilizaría en las tablas de salida donde hace referencia a esas variables.
- Las variables explicativas (es decir, X) ya están agrupadas por columnas (cada columna representa una variable), por lo que no es necesario cambiarlo.
- Por defecto, el rango de celdas de salida se establece en la celda seleccionada actualmente en la hoja de cálculo.
Tenga en cuenta que una vez que seleccionemos el rango de celdas X y Y, las pestañas "opciones", "Pronóstico" y "Valores perdidos" estarán disponibles (habilitadas).
Luego, seleccione la pestaña o tab “Opciones”
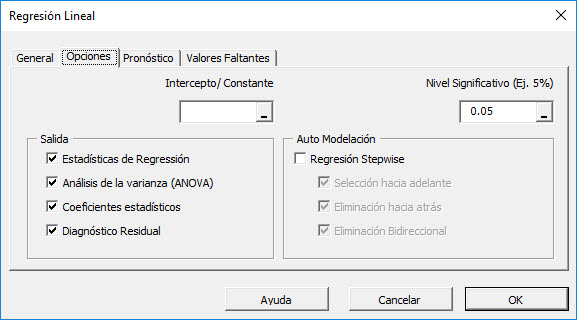
Inicialmente, la pestaña o tab e establece en los siguientes valores:
- El intercepto/constante de regresión se deja en blanco. Esto indica que la intercepto de regresión será estimada por la regresión. Para establecer la regresión a un valor fijo (por ejemplo, cero (0)), ingrese este allí.
- El nivel de significancia (aka. ) es establecido de 5%
- En la sección de resultados, se selecciona el análisis de regresión más común.
- Para auto-modelado, revise esta opción.
Ahora, clic en “Valores Falantes” tabla.
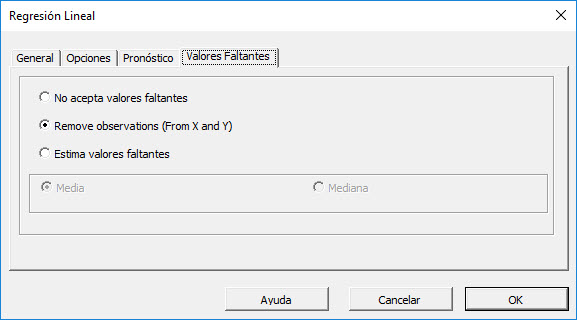
En esta pestaña o tab, puede seleccionar una aproximación para manejar valores faltantes en el conjunto de datos (X y Y). Por defecto, cualquier valor faltante encontrado en X o en Y en cualquier observación, cualquier valor faltante encontrado en X o en Y en cualquier observación excluiría la observación del análisis.
Este tratamiento es un buen enfoque para nuestro análisis, entonces vamos a dejarlo sin cambios.
Ahora, de Clic en “OK” para generar las tablas de salida.
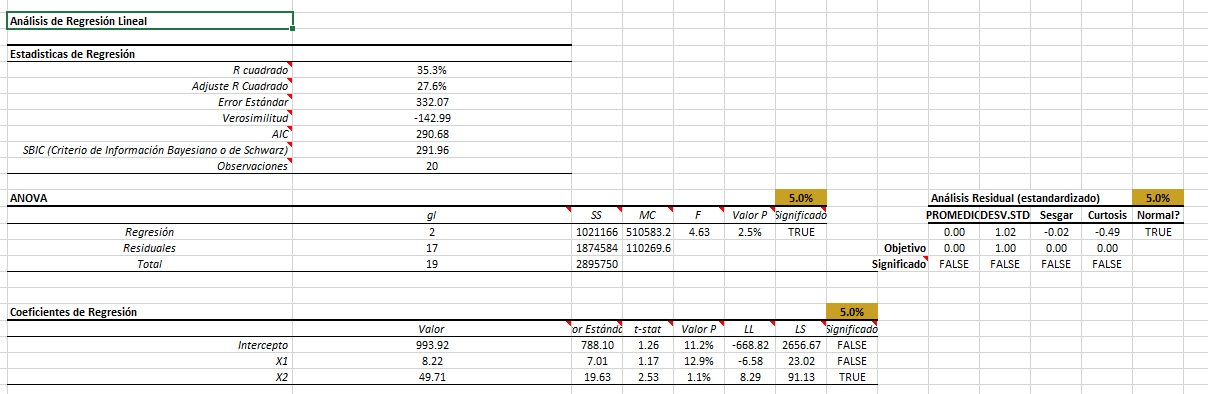
Para evaluar la influencia que cada observación ejerce sobre nuestro modelo, calculamos un par de medidas estadísticas: el apalancamiento y la distancia de Cooks.
- Seleccione la celda junto a la variable de respuesta.
- En la barra de fórmulas, escriba la función MLR_FITTED y, a continuación, haga clic en el botón "fx".
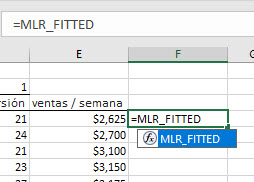
- La Función Wizard aparece. Seleccione el rango de celdas de entrada, la máscara y un tipo de retorno de 4 para las estadísticas de apalancamiento. Haga Click en “OK.”
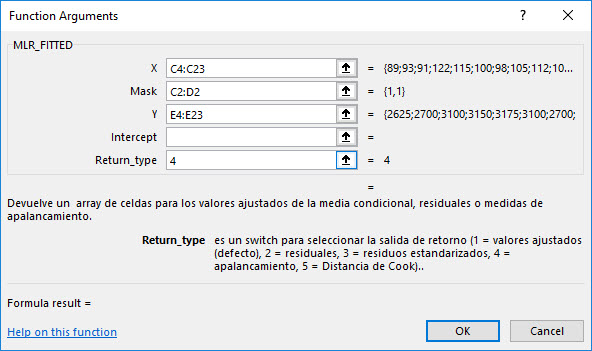
- MLR_FITTED Devuelve una matriz de valores, pero usted inicialmente sólo verá el primer valor.
- Para mostrar la matriz completa, seleccione todas las celdas a continuación (al final de la muestra).Presione F2, luego presione CTRL+SHIFT+ENTER para copiar la fórmula matricial.
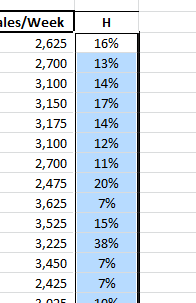
- Ahora, para calcular el distancia de cooks, Seleccione la celda junto a "Leverage" y repita los mismos pasos, pero con el tipo de retorno = 5.
Análisis
Ahora lo que tenemos es las estadísticas de apalancamiento y de distancia de Cooks, Ahora vamos a interpretar sus hallazgos.
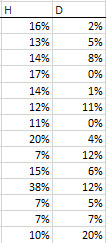
1.Estadísticas de apalancamiento(H)
La estadísticas de apalancamiento mide la distancia de una observación del centro de los datos. En nuestro ejemplo, En nuestro ejemplo, los valores de inteligencia y extroversión para el vendedor 11 están más alejados del promedio. ¿Significa esto que el vendedor 11 es un valor atípico? ¿Significa esto que ejerce influencia en el cálculo del coeficiente de regresión?
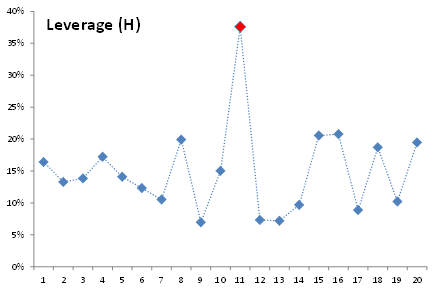
Para examinar esta suposición, vamos a eliminar al vendedor 11 de nuestros datos de entrada y examinaremos la regresión resultante. Para ello, basta con insertar un valor # N/A en cualquier variable de entrada de esta observación.
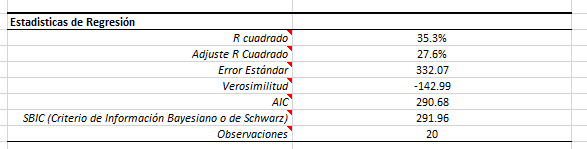
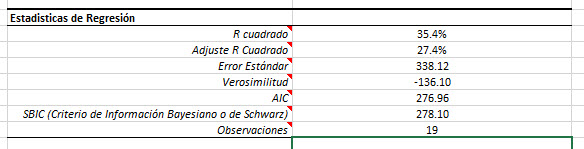
Quitando la observación 11, hace que las cosas sean por lo menos, igual que antes . Nosotros optamos por recuperar esta observación dentro de la muestra.
En suma, las estadísticas de apalancamiento no implican necesariamente un valor atípico, sino simplemente una observación distante con pocos vecinos.
2. Distancia de Cook (D)
La distancia Cooks corrige la debilidad de las estadísticas de apalancamiento y, por lo tanto, es más indicativa de datos influyentes. Además, hay pocas heurísticas para los valores umbral de la distancia de Cooks para detectar un dato influyente. Para nuestro análisis, a menudo utilizamos \frac{4}{N} Como un umbral (Que se traduce al 20% para las 20 observaciones en nuestro conjunto de datos).
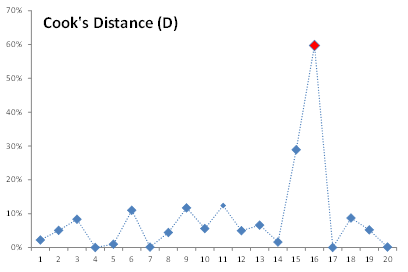
Utilizando el umbral o simplemente mirando el gráfico anterior, detectamos que el vendedor 16 ejerce la influencia más alta en nuestra regresión, así que anulemos esta observación (estableciendo # N / A en una de las variables de entrada).
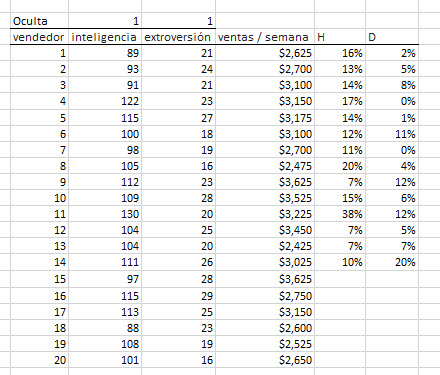
Tenga en cuenta que las estadísticas de apalancamiento y la distancia Cooks devuelven # N/A para este valor faltante.
Examinemos ahora las estadísticas de regresión antes y después de que dejáramos la decimosexta observación.
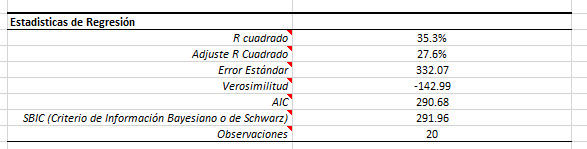
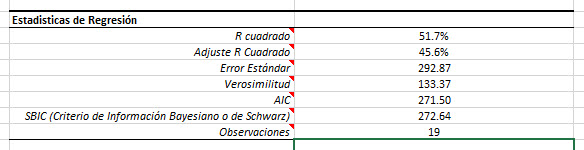
Como usted ya habrá notado, la regresión mejoró significativamente en todas las dimensiones (por ejemplo, R cuadrado, error de std, etc.). El vendedor # 16 parece ser un valor atípico (outlier) influyente, así que lo dejaremos.
Para ayudar a explicar lo que hace que una observación influyente, vamos a examinar la extroversión vs la gráfica semanal de ventas semanales a continuación:
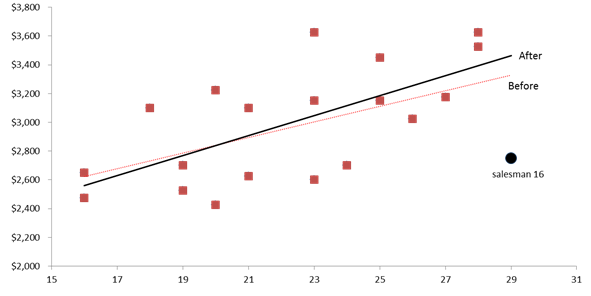
Dibujamos la tendencia lineal como un indicador para nuestro modelo de regresión. El punto de datos negro (círculo) representa al Vendedor 16. Su ubicación (extroversión y valor de ventas semanales) está tirando de la línea de regresión (punteada) hacia ella, afectando el valor de la pendiente de regresión y el intercepto.
Soltando esta observación se libera la línea de regresión, ajustándola para que se ajuste mejor a los puntos restantes.
Echemos un vistazo nuevamente a la gráfica de distancia Cooks (sin el vendedor 16, y con un umbral de $\frac{4}{19}=21%$)
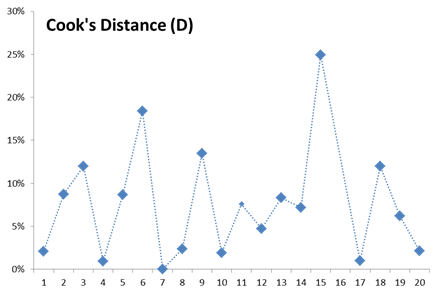
Los valores de distancia Cooks para los diferentes gráficos son distribuidos uniformemente, y podemos detenernos allí.
Nota:
Tenga en cuenta que nuestra regla de umbral es simplemente una heurística (regla general), y no debe ser tomada rígidamente, sino más bien como una pauta.
Conclusión
En este tutorial, hemos demostrado que la exclusión de observación # 16 es beneficiosa para nuestros esfuerzos de modelado, ya que ejerce una influencia significativa en nuestro cálculo de coeficientes.
Luego, usando las 19 observaciones restantes, vamos a recalcular (SHIFT+F9) Las estadísticas de regresión, ANOVA, diagnóstico de residuos, regresión escalonada, etc.
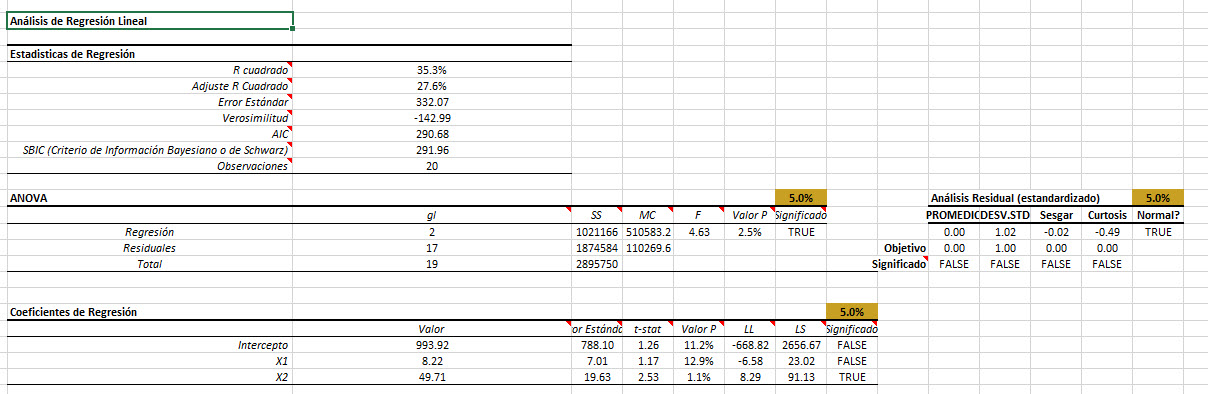
El conjunto óptimo de las variables de entrada es el mismo que anteriormente. Dejemos caer la variable de "inteligencia" (estableciendo su valor en 0 en la máscara) y recalcular.
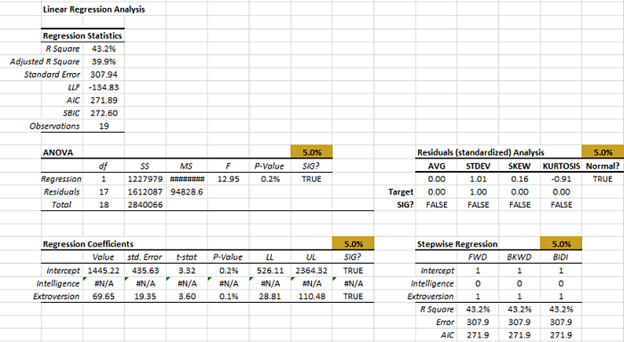
El error de regresión es \$307 (vs. \$332 before we removed salesman #16).
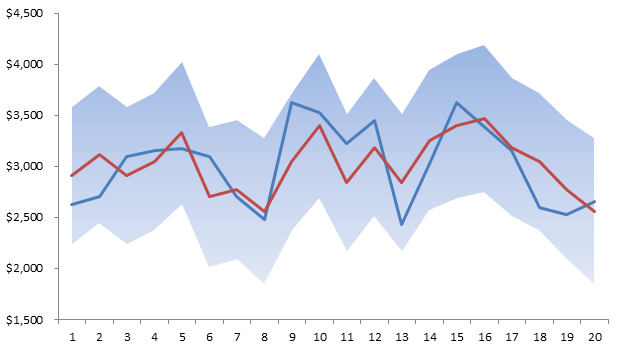
La última pregunta que podemos hacernos; ¿Es estable la regresión sobre el conjunto de datos de la muestra? Siguiente tema.
Comentarios
El artículo está cerrado para comentarios.