Esta es la segunda entrada en nuestra serie de análisis de regresión y modelado. En este tutorial, continuamos la discusión de análisis que iniciamos anteriormente y aprovechamos una técnica avanzada - la regresión por etapas en Excel - para ayudarnos a encontrar un conjunto óptimo de variables explicativas para el modelo.
Una vez más, vamos a utilizar un conjunto de datos de muestra recogidos de 20 vendedores diferentes. El modelo de regresión intenta explicar y predecir las ventas semanales de cada vendedor (variable dependiente) utilizando dos variables explicativas: inteligencia (IQ) y extroversión.
Preparación de datos
Similar a lo que hicimos en un tutorial anterior, organizamos nuestros datos de muestra colocando el valor de cada variable en una columna separada y cada observación en una fila separada.
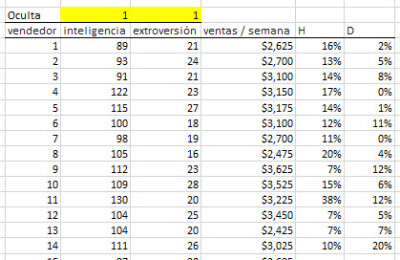
A continuación, introducimos la "máscara". La "máscara" es una matriz booleana (0,1), que elige qué variable se incluye (o excluye) del análisis.
Inicialmente, en la parte superior de la tabla, vamos a insertar la matriz de células de máscara, cada una con un valor de 1 (es decir, incluido). La matriz se muestra resaltada a continuación.
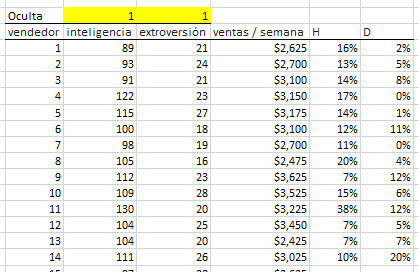
En este ejemplo, tenemos 20 observaciones y dos variables (explicativas) independientes. La respuesta o variable dependiente son las ventas semanales.
Proceso
Ahora, estamos listos para llevar a cabo nuestro análisis de regresión. En primer lugar, seleccione una celda vacía en la hoja de cálculo donde desea que se genere la salida, a continuación, busque y haga clic en el icono de regresión en la pestaña NumXL (o barra de herramientas).
![]()
Aparece el asistente de Regresión.

Seleccione el rango de celdas para los valores de la variable de respuesta / dependiente (es decir, las ventas semanales). Seleccione el rango de celdas para los valores de las variables explicativas (independientes). Para "Variables (X) Mask", seleccione las celdas en la parte superior de la tabla de datos (matriz booleana).
Notas:
- El rango de celdas incluye (opcional) la celda de encabezado ("Etiqueta"), que se utilizaría en las tablas de salida donde hace referencia a esas variables.
- Las variables explicativas (es decir, X) ya están agrupadas por columnas (cada columna representa una variable), por lo que no es necesario cambiar eso.
- De forma predeterminada, el rango de celdas de salida se establece en la celda actualmente seleccionada en su hoja de cálculo.
Tenga en cuenta que una vez que seleccionemos el rango de celdas X y Y, las pestañas "Opciones", "Pronóstico" y "Valores perdidos" comienzan a estar disponibles (habilitadas).
A continuación, seleccione la pestaña "Opciones".
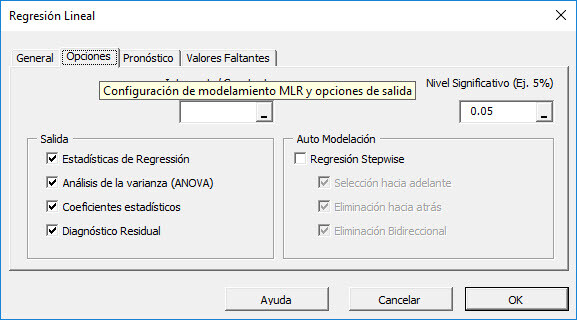
Inicialmente, la pestaña o tab se establece en los valores siguientes:
- El intercepto de la regresión se deja en blanco. Esto indica que el intercepto de la regresión será estimado por la regresión. Para ajustar la regresión a un valor fijo (Por ejemplo. zero (0)), ingrese este aquí.
- El nivel de significación (alfa. \ Alpha) se establece en 5%.
- En la sección "Salida", se seleccionan los análisis de regresión más comunes.
- Deje "Auto Modelado" sin marcar. Discutiremos esta funcionalidad posteriormente.
Ahora, click on the "Pestaña de “Valores Faltantes".

En esta pestaña, puede seleccionar una aproximación para manejar valores faltantes en el conjunto de datos (X y Y). Por defecto, cualquier valor faltante encontrado en X o en Y en cualquier observación podría excluir la observación del análisis.
Este tratamiento es un buen enfoque para nuestro análisis, así que vamos a dejarlo sin cambios.
Ahora, haga clic en "OK" para generar las tablas de salida:
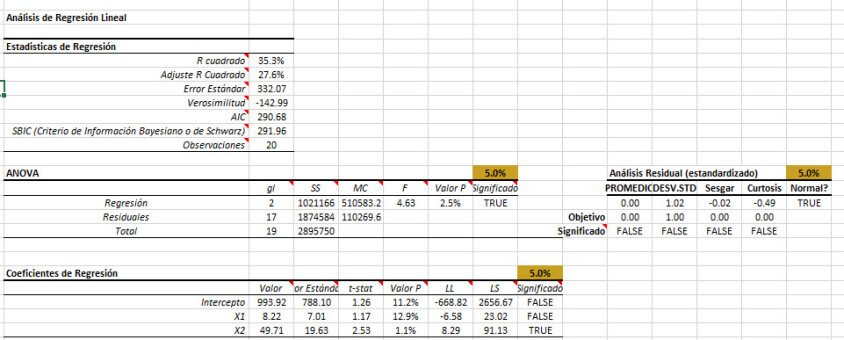
Análisis
Aparte de la configuración de "Variables (X) Mask", todo es exactamente lo mismo que lo hicimos en el tutorial anterior, así que ¿Cuál es nuestro próximo paso?
La variable "Máscara" determina qué variable se incluye en el análisis de regresión, así que vamos a echar un vistazo a la tabla de "Coeficientes".

Primero, vamos a excluir la variable de entrada "Inteligencia" del análisis. Esto se hace simplemente volteando el valor de máscara para esta celda a cero.
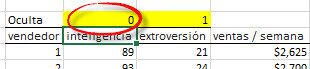
Ahora, si usted tiene la opción "Cálculo" establecida de forma manual, puede forzar el recálculo. De lo contrario, la hoja de cálculo se volverá a calcular automáticamente.

Revisando las tablas de salida, encontramos lo siguiente:
- R cuadrado disminuyó un 6%.
- R cuadrado ajustado cayó un 1,5%.
- Error estándar aumentó en 3.
- AIC cayó por uno (1).
- La tabla ANOVA muestra que la regresión es significativa.
- El diagnóstico residual revisa todas las pruebas.
- En la tabla de coeficientes de regresión, el intercepto y el coeficiente de la variable "Extroversión" ambos son estadísticamente significativos.
Este modelo tiene menos parámetros (es decir uno) y explica la variación en los valores de la variable de respuesta tan bien como cuando teníamos dos (2) variables explicativas.
Ahora, vamos a trazar los valores estimados contra el real.
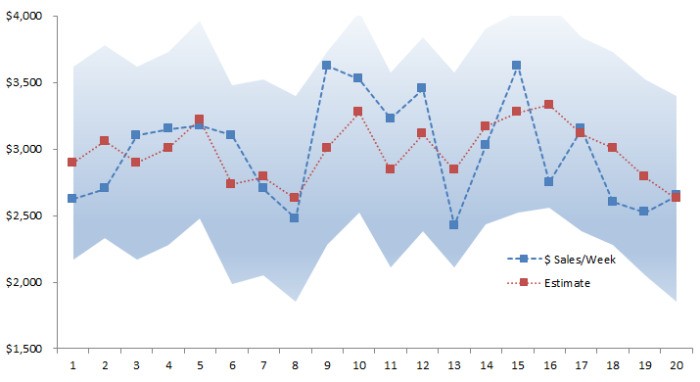
El área sombreada representa el intervalo de confianza del 95% para las estimaciones del modelo de regresión.
Hasta ahora, hemos demostrado que eliminar una variable del análisis es tan fácil como mover un interruptor; No más copia de datos y la saturación de su hoja de cálculo con toneladas de tablas de salida. Esto está bien, pero usted puede ser que se esté preguntando: si tenía más variables explicativas (digamos 10), ¿Cuál es el conjunto óptimo de variables? ¿Debo probar cada subconjunto?
NumXL soporta una funcionalidad interesante – Regresión escalonada en Excel – Para ayudarle a seleccionar este conjunto óptimo. Vamos a demostar cómo puede usarlo.
- En el rango de celdas "Máscara", active o desactive las variables que usted desee que la regresión escalonada en Excel considere. Para esta demostración, las activaremos todos.
- Busque y haga clic en el icono de regresión en la pestaña NumXL.
- Aparece el Asistente de Regresión.
- En la pestaña "General", seleccione el rango de celdas de entrada y el rango de celdas de máscara.
- En la ficha Opciones, marque la casilla "Regresión escalonada".
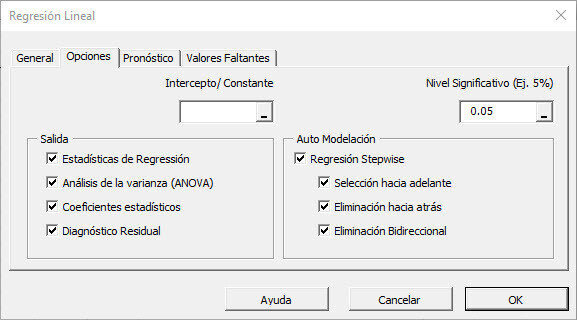
- Deje los 3 métodos diferentes marcados.
- De Clic en “OK.”
- Las tablas de salida son generadas.
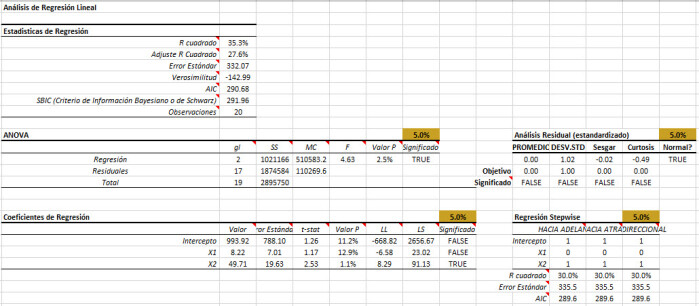
La regresión paso a paso en Excel genera una tabla adicional junto a la tabla de coeficientes.
Vamos a ver un vistazo más de cerca esta nueva tabla.
La regresión escalonada lleva a cabo una serie de pruebas parciales F para incluir (o eliminar) variables del modelo de regresión.
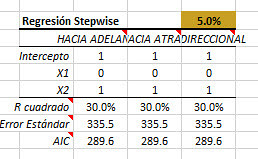
- Selección directa: comenzamos con una intercepción, y examinamos la adición de una variable adicional.
- Eliminación hacia atrás: Partimos del modelo completo con todas las variables, y consideramos la posibilidad de eliminar un represor a la vez.
- La eliminación bidireccional es un híbrido de los dos métodos.
Comentarios
El artículo está cerrado para comentarios.