En una entrada anterior, discutimos el histograma como un método no paramétrico para la inferencia de distribución de probabilidad de una variable aleatoria. En este tutorial, repasamos la función de distribución empírica y estimamos sus valores para los diferentes puntos de la muestra.
Para los datos de muestra, se generó un conjunto de datos de 29 valores generados aleatoriamente de la distribución Gaussiana.
Fondo
La función de distribución empírica (FED) o cdf empírica es una función de paso que salta por 1/N a la ocurrencia de cada observación:
$$FDE(x)=\frac{1}{N}\sum_{i=1}^N I\{x\leq x_i\}$$
Donde
- $\{A\}$ es el indicador de la función de un evento
- $I\{x\leq x_i\}=\begin{cases} 1 & \text{ if } x \leq x_i \\ 0 & \text{ if } x \gt x_i \end{cases}$
Por definición, la función FDE calcula la distribución acumulativa del número aleatorio subyacente.
Por qué nos preocupamos?
El FED estima la verdadera función de densidad acumulativa subyacente de los puntos en la muestra; Se garantiza virtualmente que converge con la distribución verdadera a medida que el tamaño de la muestra se hace lo suficientemente grande.
Proceso
Primero, vamos a organizar nuestros datos de entrada. Nosotros podemos comenzar ubicando los valore de loss datos de la muestra en una columna separada. La muestra puede contener uno o más valores faltantes.
Ahora estamos listos para construir nuestro FDE Plot First, seleccione la celda vacía en la hoja de trabajo donde desea que se genere la tabla de salida, luego busque y haga clic en el icono "Estadísticas Descriptivas" en la pestaña NumXL (o barra de herramientas). A continuación, seleccione el elemento "Función de distribución empírica" del menú desplegable.
El Wizard o asistente FDE Wizard aparece.
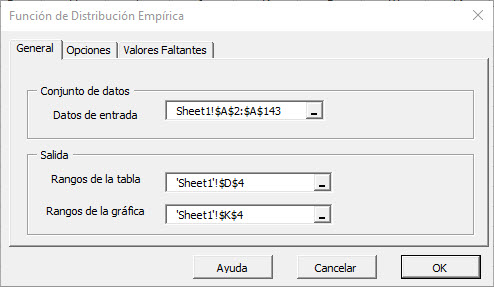
Seleccione el rango de celdas para los valores de la variable de entrada.
Notas:
- El rango de celdas incluye (opcional) la celda de encabezado ("Etiqueta"), que podria ser utilizada en las tablas de salida donde esta hace referencia a esas variables.
- Por defecto, el rango de celdas de la tabla de salida se establece en la actual celda seleccionada en su hoja de cálculo.
- Por defecto, El rango de las celdas del gráfico de salida se establece en las 7 celdas a la derecha de la celda seleccionada actualmente en la hoja de cálculo.
Finalmente, una vez que seleccionamos el rango de las celdas de datos de entrada (X), las pestañas "Opciones" y "Valores faltantes" están disponibles (activadas).
Luego, seleccione l pestaña opciones
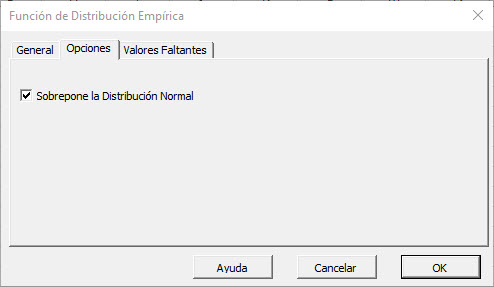
Inicialmente, la tab o pestaña se establece para los siguientes valores:
- "Superposición de distribución Normal" está activada. En efecto, esta opción instruye al wizard o asistente a generar una segunda curva de la distribución Gaussiana para propósitos de comparación. Deje esta opción marcada.
Ahora, de clic en la pestaña Now, “Valores Faltantes”.
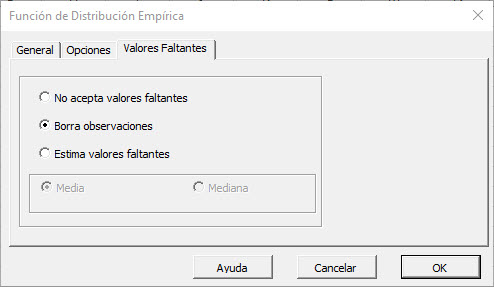
En esta pestaña, usted puede seleccionar un enfoque para manejar los valores que faltan en el conjunto de datos (de X). Por defecto, cualquier observación con valor faltante sería excluida del análisis.
Este tratamiento es un buen enfoque para nuestro análisis, así que vamos a dejarlo sin cambios.
Salida
Ahora de clic en “OK” para generar las tablas de salida.
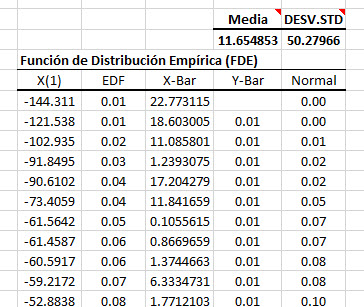
Notas:
- Los valores de todas las observaciones son ordenados en orden ascendente y ubicados en la columna E.
- Las columnas X-Bar y Y-Bar no tienen significado estadístico especial; Se calculan simplemente para ayudarnos a generar un tipo de gráfico paso a paso en Excel.
- Finalmente, la función de densidad acumulativa equivalente (CDF) de la distribución normal se calcula en la columna I.
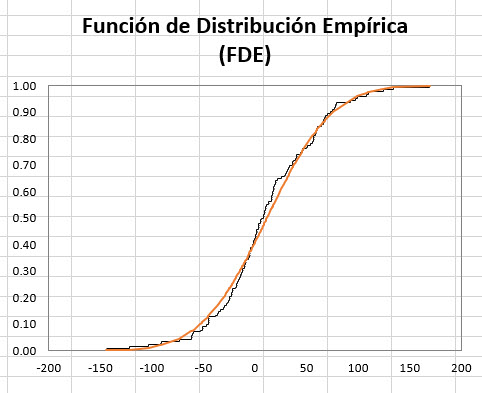
El gráfico generado del FDE se muestra a continuación:
Conclusión
En este tutorial, hemos demostrado el proceso para generar una función de distribución empírica en Excel utilizando las funciones complementarias de NumXL.
¿A dónde vamos desde aquí?
Para obtener la función de densidad de probabilidad (PDF), se necesita tomar la derivada de la CDF, pero el FDE es una función escalonada y la diferenciación es una operación de amplificación de ruido. Como resultado, el PDF resultante es muy recortado y necesita un suavizado considerable para muchas áreas de aplicación.
En nuestra próxima entrada, examinaremos el método de estimación de la densidad del núcleo para obtener la función de densidad de probabilidad del proceso aleatorio subyacente.
Comentarios
El artículo está cerrado para comentarios.