Esta es nuestra segunda entrada del análisis de componentes principales (ACP) en Excel series. En este tutorial vamos a resumir nuestra discusión en la reducción de la dimensión usando un subconjunto de los componentes principales con una pérdida mínima de información.Vamos a utilizar NumXL y Excel para llevar a cabo nuestro análisis, examinando de cerca los diferentes elementos de salida en un intento de desarrollar una sólida comprensión de ACP, que preparará el camino a un tratamiento más avanzado en las ediciones futuras.
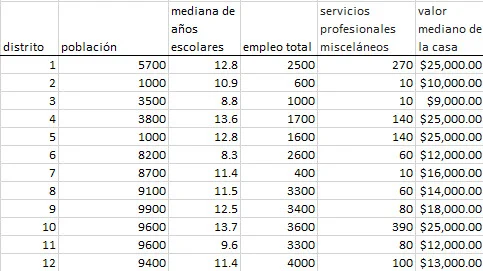
En este tutorial, seguiremos utilizando los datos socioeconómicos proporcionados por Harman (1976). Las cinco variables representan población total ("Población"), mediana de años escolares ("Escuela"), empleo total ("Empleo"), servicios profesionales diversos ("Servicios") y valor mediano de vivienda. Cada observación representa uno de los doce tramos del censo en el área metropolitana estadística de Los Ángeles.
Proceso
Ahora estamos listos para realizar nuestro análisis de componentes principales en Excel. En primer lugar, seleccione una celda vacía en la hoja de cálculo en la que desea que se genere la salida, a continuación, busque y haga clic en el icono de componente principal (ACP) en la ficha NumXL (o barra de herramientas).
![]()
Aparecerá el Asistente de Regresión.
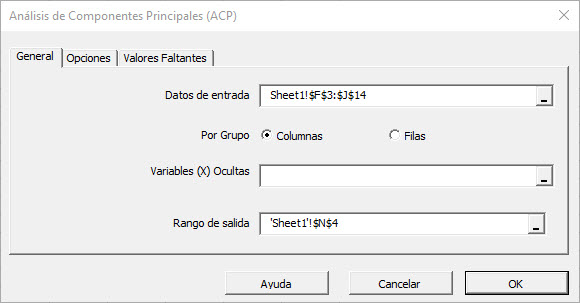
Seleccione el rango de celdas para los cinco valores de las variables de entrada.
Notas:
- El rango de celdas incluye (opcional) la celda de encabezado (etiqueta), que se utilizaría en las tablas de salida donde hace referencia a esas variables.
- Las variables de entrada (es decir, X) ya están agrupadas en columnas (cada columna representa una variable), por lo que no es necesario cambiarlo.
- Deje el campo de "Variables Mask" en blanco por ahora. Revisaremos este campo en entradas posteriores.
Ahora, seleccione la pestaña “Opciones”.
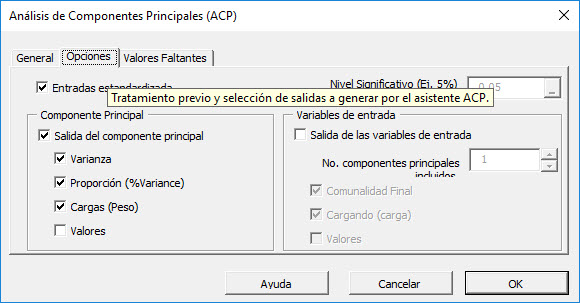
Inicialmente, la pestaña se establece en los valores siguientes:
- "Estandarizar entradas" está marcada. Deje esta opción marcada.
- Se selecciona "Salida de componente principal". Desmarque la casilla.
- El nivel de significación (aka. $\alpha$) Se establece en 5%.
- "Variables de entrada" está desmarcada. Marque esta opción.
- Set "No. De PCs incluidos "a 3. Esta acción puede realizarse ahora o alterarse posteriormente en las tablas de resultados, ya que nuestras fórmulas son dinámicas.
- En "Variables de entrada", marque la opción "Valores", por lo que las tablas de salida generadas incluyen un valor ajustado para las variables de entrada usando un conjunto reducido de componentes.
Ahora, haga clic en la pestaña "Valores faltantes".
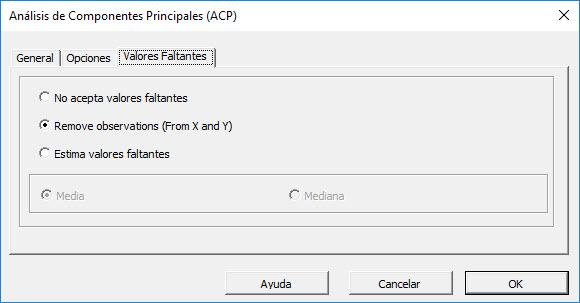
En esta pestaña o tab, puede seleccionar una aproximación para manejar valores faltantes en el conjunto de datos (X y Y). De forma predeterminada, cualquier valor perdido encontrado en cualquier observación excluiría la observación del análisis.
Este tratamiento es un buen enfoque para nuestro análisis, así que dejémoslo sin cambios.
Ahora, haga clic en "Aceptar" para generar las tablas de resultados.
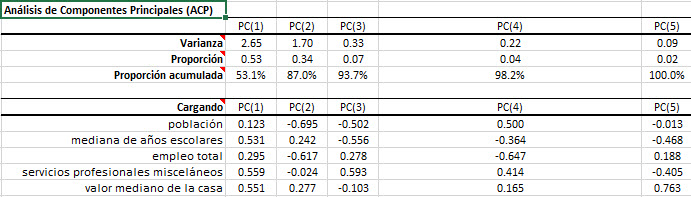
Análisis
1. Estadística

En esta tabla, mostramos el porcentaje de varianza de cada variable de entrada que se contabilizó (también conocida como comunidad final) usando los primeros tres (3) factores. A diferencia de la proporción acumulada, esta estadística se relaciona a una variable de entrada a la vez.
Usando esta tabla, podemos detectar qué variables de entrada están mal presentadas (es decir, afectadas adversamente) por nuestra reducción de dimensión. En este ejemplo, la "mediana de años escolares" tiene el valor más bajo, sin embargo, la comunalidad final es todavía alrededor del 92%.
2. Cargas
En la tabla de carga, describimos las cargas del componente principal en cada variable de entrada:
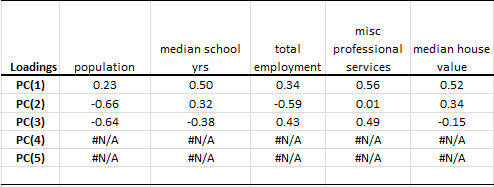
Para calcular los valores de una variable de entrada usando valores de CP, usamos los pesos anteriores para transformarlos linealmente de nuevo. Por ejemplo, el factor de población se expresa de la siguiente manera:
$$\hat X_1=0.23PC_1-0.66PC_2-0.64PC_3$$
Notas:
- Esta tabla es básicamente la tabla transpuesta (fila convertida en columnas) que vimos en las cargas de las variables para componentes principales.
- La suma de los cuadrados de cada fila debe ser 1.
- $PC_1,PC_2,\cdots, PC_m$ No están correlacionados, por lo que para calcular la varianza de$X_1$(Standarized),utilizando los primeros componentes k:
$$Var(\hat X_i)=\gamma_1^2\sigma_1^2+\gamma_2^2\sigma_2^2+\cdots+\gamma_k^2\sigma_k^2 \leq 1$$ $$X_i=\frac{x_i-\bar x_i}{\sigma_{x_i}}$$ $$\gamma_1^2\sigma_1^2+\gamma_2^2\sigma_2^2+\cdots+\gamma_m^2\sigma_m^2=1$$ Donde:- $\gamma_k$ es la carga del k-ésimo componente principal para la $X_i$ variable de entrada.
- $\sigma_k^2$ es la varianza del k-ésimo componente principal.
- $X_i$ es el estimado para la variable de entrada estandarizada utilizando los primeros componentes k.
- Por definición la $Var[\hat X_i]$ es la comunalidad final.
- La varianza de la variable de entrada ajustada en la escala original (no estandarizada) se expresa de la siguiente manera:
$$Var[ \hat{x_i} ]=(\gamma_1^2\sigma_1^2+\gamma_2^2\sigma_2^2+\cdots+\gamma_k^2\sigma_k^2)\times \sigma_{x_i}^2$$ - Reducir la dimensión, en esencia, reduce la varianza de las variables de entrada (filtro de paso bajo).
- ¿Qué pasa con la correlación entre las variables originales? ¿Cómo se ven afectadas por la reducción de las dimensiones?
$$\hat X_i=\gamma_1PC_1+\gamma_2PC_2+\cdots+\gamma_kPC_k$$ $$\hat X_j=\omega_iPC_1+\omega_2PC_2+\cdots+\omega_kPC_k$$ $$Cov[\hat X_i, \hat X_j]=\sigma_{\hat X_i,\hat X_j}=E[\hat X_i \times \hat X_j]=E[\gamma_1\omega_1PC_1^2+\gamma_2\omega_2PC_2^2+\cdots+\gamma_k\omega_kPC_k^2 ]$$ $$Cov[\hat X_i, \hat X_j]=\rho_{\hat x_i,\hat x_j}= \sum_{i=1}^k \gamma_i\omega_i\sigma_i^2$$ $$Cov[X_i, X_j]=\rho_{x_i,x_j}= \sum_{i=1}^m \gamma_i\omega_i\sigma_i^2=\sigma_{\hat X_i,\hat X_j}+\sum_{i=k+1}^m \gamma_i\omega_i\sigma_i^2$$ $$Cov[\hat X_i, \hat X_j] = Cov[X_i, X_j] - \sum_{i=k+1}^m \gamma_i\omega_i\sigma_i^2$$ Donde:- $\hat X_i$ Es la i-ésima variable ajustada estandarizada utilizando los primeros k componentes principales k.
- $X_i$es la variable de entrada i-ésima estandarizada original.
- $x_i$es la variable de entrada i-ésima original.
- $\hat x_i$es la variable de entrada i-ésima ajustada no estandarizada usando el primer componente k-principal.
- ¿Qué hay de la covarianza entre las variables (no estandarizadas)? $$\hat X_i = \frac{\hat x_i-\bar x_i}{\sigma_{x_i}}\Rightarrow \hat x_i-\bar x_i=\hat X_i \times \sigma_{x_i}$$ $$Cov[\hat x_i,\hat x_j]=E[(\hat x_i-\bar x_i)(\hat x_j-\bar x_j)]=\sigma_{x_i}\sigma_{x_j}E[\hat X_i\hat X_j]$$ $$Cov[\hat x_i,\hat x_j]=\sigma_{x_i}\sigma_{x_j}\times (\sigma_{X_i,X_j}-\sum_{i=k+1}^m \gamma_i\omega_i\sigma_i^2)$$ $$Cov[\hat x_i,\hat x_j]=Cov[x_i,x_j]-\sigma_{x_i}\sigma_{x_j}\sum_{i=k+1}^m \gamma_i\omega_i\sigma_i^2$$
En suma, el cambio relativo en la covarianza es igual al cambio en la correlación entre las dos variables.
Nota: La reducción del número de factores altera las características estadísticas del conjunto de datos subyacentes, por lo que se debe tener mucho cuidado.
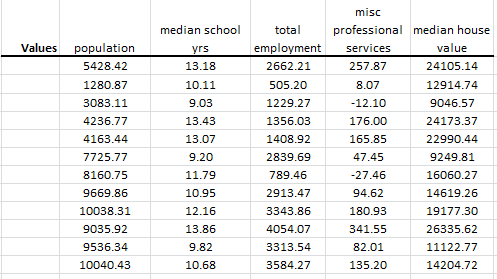
Valores ajustados
Usando los primeros tres (3) componentes principales, NumXL calcula el valor ajustado para cada variable de entrada:
Nota:
Aunque el análisis de componentes principales en Excel utiliza la versión estandarizada de las variables de entrada, este calcula los valores ajustados en el formato no normalizado original.
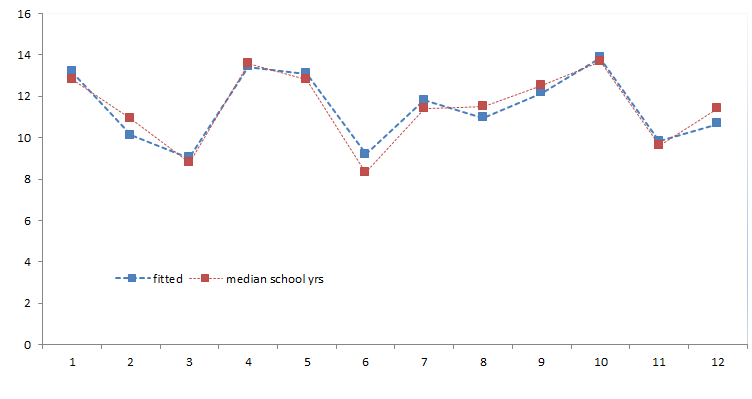
Vamos a trazar la población (comunidad final más alta) y los años escolares medianos (comunidad final más baja) para los datos originales y para los ajustados.

Conclusión
En este tutorial, examinamos la propuesta de reducción de dimensión de 5 CPs a 3 CPs sin pérdida significativa de información.
¿Que hacemos ahora?
En los dos primeros tutoriales, nos enfocamos en entregar las ideas clave detrás del análisis de componentes principales y, hasta cierto punto, en la justificación detrás de la propuesta de reducción de dimensiones. Los datos de muestra socioeconómica de la sección transversal, aunque no una serie de tiempo, sirvieron para demostrar la teoría y para mostrar las diferentes tablas de salida de NumXL.
En la tercera entrada de esta serie, estamos listos para mirar en un conjunto de series de tiempo correlacionadas, aplicar la técnica de ACP para derivar un pequeño conjunto básico de conductores no correlacionados. A continuación, pronosticaremos los valores (media y error estándar) para los conductores no correlacionados, y utilizando las cargas del ACP, y deduciremos el pronóstico correspondiente (media y error) para cada variable de entrada.
Comentarios
El artículo está cerrado para comentarios.